
“Data alone isn’t power; AI that turns data into actionable insight is the real game changer for enterprises.”
In recent years, enterprises get drowning in unstructured data from legal documents and research reports to customer tickets and policy manuals discovered that traditional AI often delivered generic answers, costing time and money. That changed with Retrieval‑Augmented Generation (RAG). Companies adopting RAG report up to 85% higher trust in AI outputs, 40–60% fewer factual errors, and internal search speeds 40% faster than before, transforming how teams access knowledge and make decisions.”
In today’s fast-paced digital world, enterprises are under constant pressure to leverage data for smarter decision-making, faster innovation, and enhanced customer experiences. Pressed by the furious rhythms of the digital world, enterprises have to continuously work out how to use data for wiser decision-making, quicker innovation, and improved customer experiences. Welcome Google Cloud’s Vertex AI: it’s an all-singing, all-dancing machine learning platform changing enterprise strategy when it comes to developing, deploying, and scaling artificial intelligence solutions. Of the many contrasting features on this fantastic machine learning platform, few could be said to be as life-changing as the RAG Engine-what it is, exactly?
What is Vertex AI?
Vertex AI is a machine learning (ML) platform that lets you train and deploy ML models and AI applications. Vertex AI combines data engineering, data science, and ML engineering workflows, which lets teams collaborate using a common toolset.
The key services within Vertex AI are:
- Auto-ML & Custom Training: Train models without the need for advanced ML skills or build models from scratch.
- Feature Store & Model Registry: Effective management and reuse of features and models.
- Vertex Pipelines: Automates ML tasks for continuous training and deployment.
- Model Monitoring & Explained AI: Monitoring for model drift and providing explanations for predictions.
Vertex AI provide training on both server less training and training clusters.
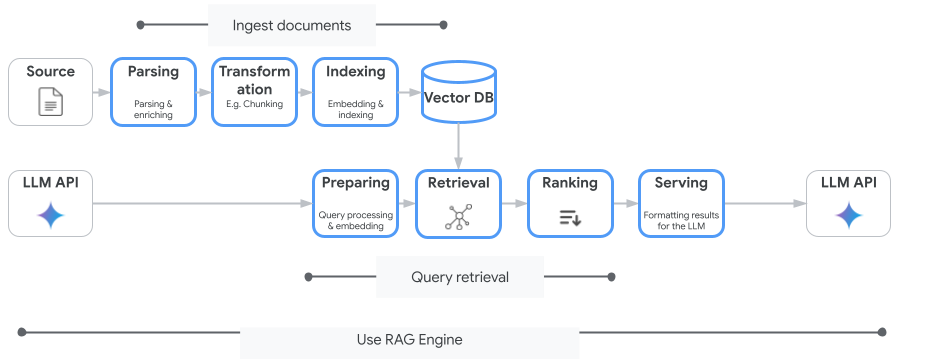
These concepts are listed in the order of the retrieval-augmented generation (RAG) process.
- Data ingestion: Ingest data from other sources. For example, from local files, Cloud Storage, or Google Drive.
- Data Transformation: The process of preparing the data for indexing. This includes, for instance, the data being broken into chunks.
- Embedding: This is the numerical representation of a word or a piece of texts. These numbers represent the meaning of the texts. Similar or related texts or words have similar embeddings. This is because they are closer in the vector space.
- Data Indexing: The Vertex AI RAG Engine builds an index that is called a corpus. The index organizes information in the knowledge base in a way that makes the information easily searchable. The index, for instance, is like the contents page in an enormous book of reference.
- Retrieve: When a user posts a question or enters a prompt, the retrieve component in the Vertex AI RAG Engine looks through its knowledge base for data that relates to that question or prompt.
- Generation: The extracted data for a given query thread serves as context that is added to a user query as a clue for a generative AI model for response generation.
Customization:
Among the unique and prominent strengths of the RAG Engine found in the Vertex AI platform is the ability to perform customization. With this feature, you can optimize a variety of components according to your data, among other things.
- Parsing: When the documents are fed into an index, they are broken into pieces called chunks. RAG Engine offers the ability to adjust the amount of a chunk, overlap of a chunk, and approaches based on the different nature of the documents.
- Retrieval: perhaps you already use Pinecone, or maybe you like the open source abilities that We aviate has to offer. Alternatively, maybe you’d like to make use of the Vertex AI Vector Search output or our Vector database. The RAG Engine will work with whatever you decide to utilize or offer to help you with the vector storage.
Generation MLSs offered in Vertex AI Model Garden are in the hundreds and include Gemini and Claude from Google and Llama.
Vertex AI RAG Engine revolutionizes enterprise AI by enabling Retrieval-Augmented Generation (RAG) that grounds large language models in proprietary data, reducing hallucinations and boosting accuracy. This managed service automates ingestion, chunking, embeddings, indexing, retrieval, and generation for scalable, low-latency applications. Enterprises leverage it for knowledge-intensive tasks across finance, healthcare, and IT.
The engine cuts hallucinations by anchoring responses in trusted data, turning LLMs into “enterprise knowledge workers” for real-time queries. It offers enterprise-grade scalability, privacy controls, and governance, handling large corpora with low latency—critical for production RAG systems.
Traditionally, building and deploying a single model required stitching together a patchwork of siloed tools for data preparation, experimentation, training, deployment, and monitoring—each with its own learning curve, integration challenges, and scaling limits. This “toolchain tax” consumed over 80% of data scientists’ time on plumbing rather than innovation, causing projects to stall or fail. Vertex AI dismantles this barrier by offering a single, unified platform where every step of the ML workflow—from automated data labeling and no-code AutoML to custom TensorFlow/PyTorch training, integrated MLOps with Vertex Pipelines, and unified model registry—coheres seamlessly. This consolidation is transformative; it slashes development cycles from months to weeks, ensures governance and reproducibility by design, and enables a “factory” approach to AI where models can be reliably built, compared, and deployed at scale.
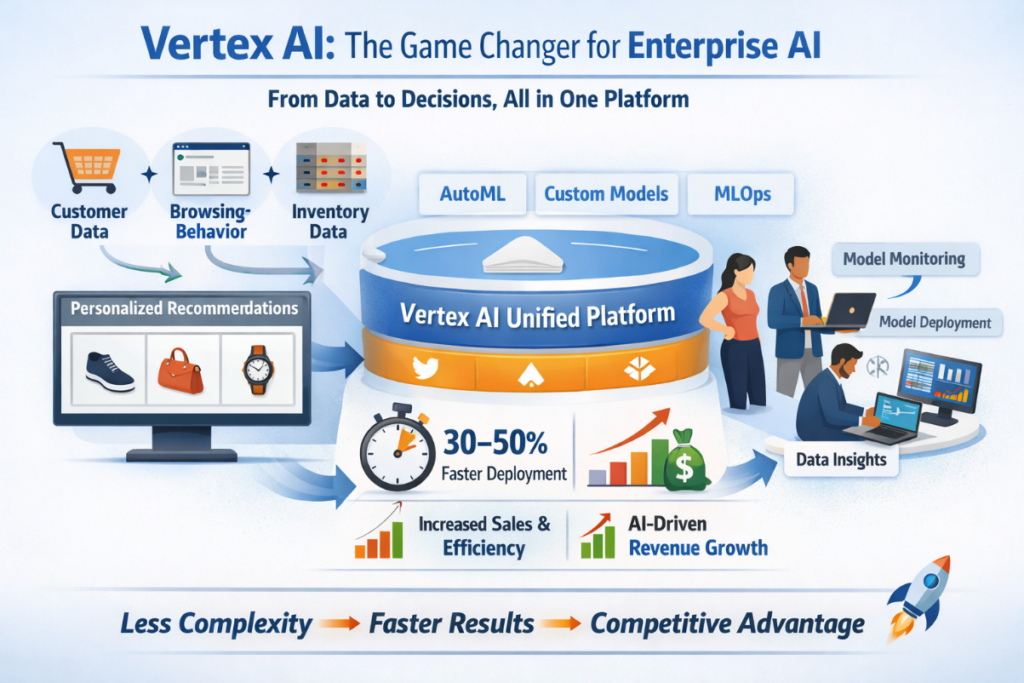
This picture visually explains how Vertex AI acts as a unified, end-to-end AI platform for enterprises. On the left, multiple business data sources—customer data, browsing behavior, and inventory data—flow into the system, showing how real-world enterprise data is collected from different channels. At the center, the Vertex AI Unified Platform acts as the core engine, integrating AutoML, custom model development, and MLOps, which highlights how companies can build, train, deploy, and manage models in one place instead of using fragmented tools. On the right, teams are shown working with model deployment, monitoring, and data insights, representing real operational use in business environments. The bottom section emphasizes measurable business impact, such as 30–50% faster deployment, increased sales and efficiency, and AI-driven revenue growth, concluding with the idea that Vertex AI reduces complexity, speeds up results, and gives enterprises a strong competitive advantage.
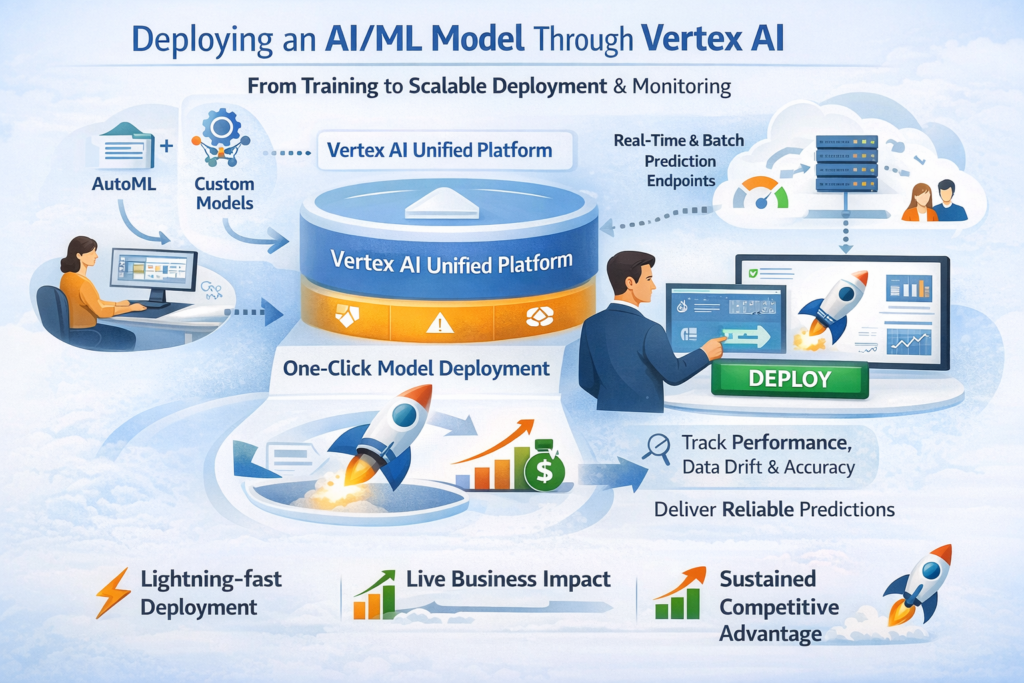
In conclusion, the image demonstrates how Vertex AI simplifies the journey from model training to scalable deployment through a unified platform. It highlights one-click deployment, real-time predictions, and continuous monitoring as key strengths. Ultimately, Vertex AI transforms AI models into reliable, production-ready solutions that drive real business impact and competitive advantage.



